Rebalancing Partitions
In a database, things can change over time. For example, when more people are using it, you might need to add more computing power. If the amount of data gets bigger, you may want to add more storage space and memory. Sometimes, a machine might stop working, and others have to take on its tasks.
When any of these changes occur, data and requests may need to be moved from one machine to another. This process of shifting work from one machine to another is called rebalancing.
Regardless of which partitioning scheme is used, when rebalancing happens, there are a few basic things we want:
- After rebalancing, the work (like storing data, and handling read and write requests) should be divided fairly among all the machines.
- Even when rebalancing is going on, the database should still be able to handle new requests for reading and writing data.
Strategies for Rebalancing
Problem with Hash Mod N
When using hash partitioning (as discussed earlier), where we divide possible hashes into ranges and assign each range to a partition, the mod N approach can lead to issues.
In the mod N approach, if the number of nodes N changes, most keys will have to be moved from one node to another. For instance, if hash(key) equals 123456 and you start with 10 nodes, the key is on node 6 (because 123456 mod 10 equals 6). If you grow to 11 nodes, the key must move to node 3 (123456 mod 11 equals 3), and if you expand to 12 nodes, it has to move to node 0 (123456 mod 12 equals 0). This frequent key movement makes rebalancing extremely costly and inefficient.
Fixed Number of Partitions
To address the challenge of dynamic node changes, a simple solution involves creating a surplus of partitions compared to the number of nodes. Multiple partitions are then assigned to each node. For example, in a 10-node cluster, the database may begin with 1,000 partitions, distributing around 100 partitions to each node.
When a new node joins, it can acquire a few partitions from each existing node until an even distribution is restored. Conversely, if a node is removed, the process reverses.
Importantly, only complete partitions are moved between nodes. The total number of partitions and the key-to-partition assignments remain constant. The sole adjustment is the reassignment of partitions to nodes. However, this reassignment isn’t instantaneous—it takes time to transfer a large amount of data over the network. During this transfer, the old partition assignment is used for any ongoing reads and writes.
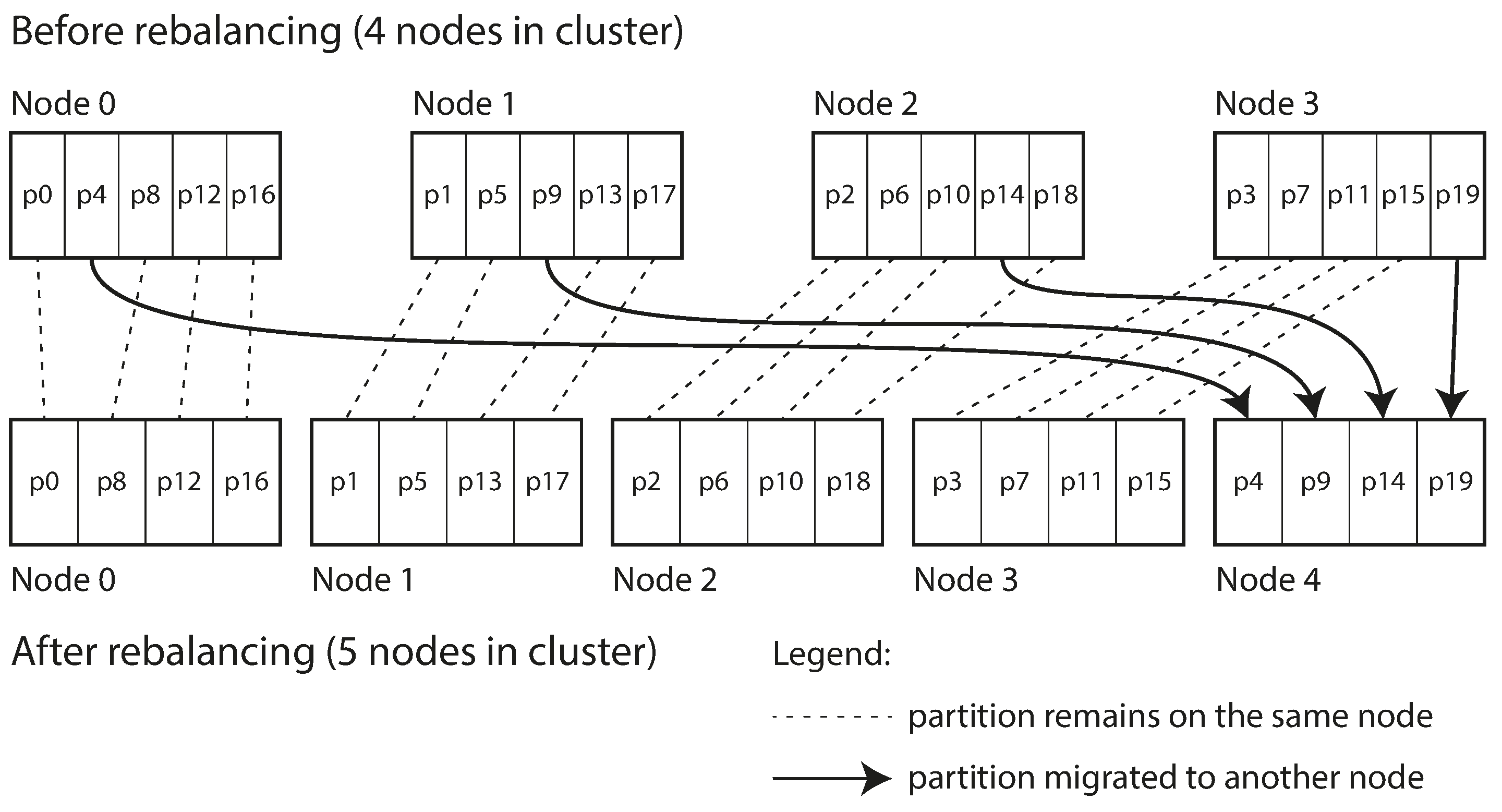
In this setup, the number of partitions is typically established during the initial database setup and remains constant thereafter. It’s crucial to choose a number high enough to accommodate future growth, yet not so high that it introduces excessive management overhead.
Determining the optimal number of partitions becomes challenging when the dataset size varies significantly. Larger partitions can make rebalancing and recovering from node failures costly, while overly small partitions result in excessive overhead. The ideal performance is achieved when partition size is balanced, neither too large nor too small.
Dynamic Partitioning
To address the challenges of fixed partitions, databases like HBase and RethinkDB employ dynamic key range–based partitioning. In this approach, partitions are created and adjusted dynamically based on data size:
Dynamic Partition Creation: As a partition approaches a configured size limit (e.g., 10 GB in HBase), it is split into two, distributing roughly half of the data on each side of the split.
Merging Small Partitions: Conversely, if a partition shrinks below a certain threshold due to data deletion, it can be merged with an adjacent partition.
Load Balancing: After splitting a large partition, one of its halves can be moved to another node to balance the overall load. In HBase, this involves transferring partition files through its distributed filesystem, HDFS.
Dynamic partitioning offers the advantage of adapting the number of partitions to the total data volume. However, a drawback is that an empty database starts with a single partition. Until the dataset grows and the first partition is split, all writes are handled by a single node, while other nodes remain inactive.
To address this, databases like HBase and MongoDB allow the configuration of an initial set of partitions on an empty database, a practice known as pre-splitting. This helps distribute the load more evenly from the start, mitigating the issue of a single node handling all writes in the early stages of a small dataset.