Secondary indices
When records are exclusively accessed through their primary key, the partition can be derived from that key. This enables the routing of read and write requests to the specific partition responsible for that key.
Secondary indexes, on the other hand, typically don’t uniquely identify a record. Instead, they serve as a means to search for occurrences of a specific value. For example, you can find all transactions over $100, locate articles related to technology trends, or identify all properties with more than four bedrooms.
Secondary indexes play a crucial role in relational databases and are also widely utilized in document databases.
Partitioning Secondary Indexes by Document:
To facilitate user searches for cars based on color and brand, you implement a secondary index on color and brand (considered as fields in a document database or columns in a relational database). Once the index is declared, the database automatically performs the indexing. For instance, adding a red car to the database results in the automatic inclusion of its document ID in the index entry for color:red.
In this indexing methodology, every partition operates as an independent entity. Each partition autonomously manages its set of secondary indexes, exclusively encompassing the documents residing within that specific partition. The partition remains oblivious to the data stored in other partitions.
When interacting with the database—whether to add, remove, or update a document—the operation only deals with the specific partition housing the targeted document ID. Hence, it is also known as local index.
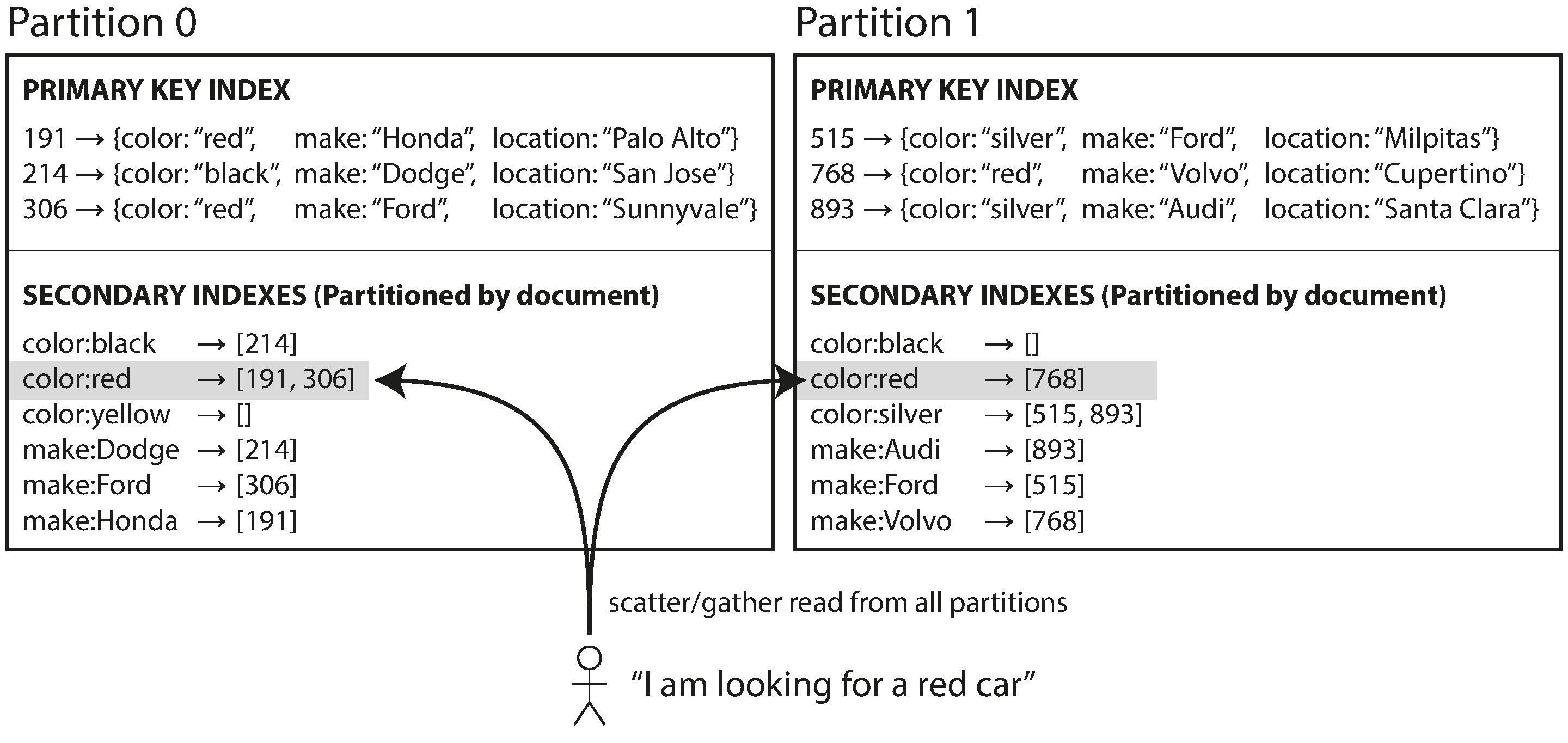
When searching for red cars, a query needs to be distributed across all partitions, and the results must be aggregated. This querying method, referred to as scatter/gather, can make read queries on secondary indexes relatively costly. Even with parallelized partition querying, scatter/gather is susceptible to tail latency amplification.
Partitioning Secondary Indexes by Term:
In contrast to having each partition possess its individual secondary index (local index), a global index covering data across all partitions can be constructed. However, storing such a global index on a single node may become a bottleneck, defeating the purpose of partitioning. To address this, the global index is also partitioned, although differently from the primary key index.
This type of index is termed term-partitioned, where the partition of the index is determined by the term being searched.
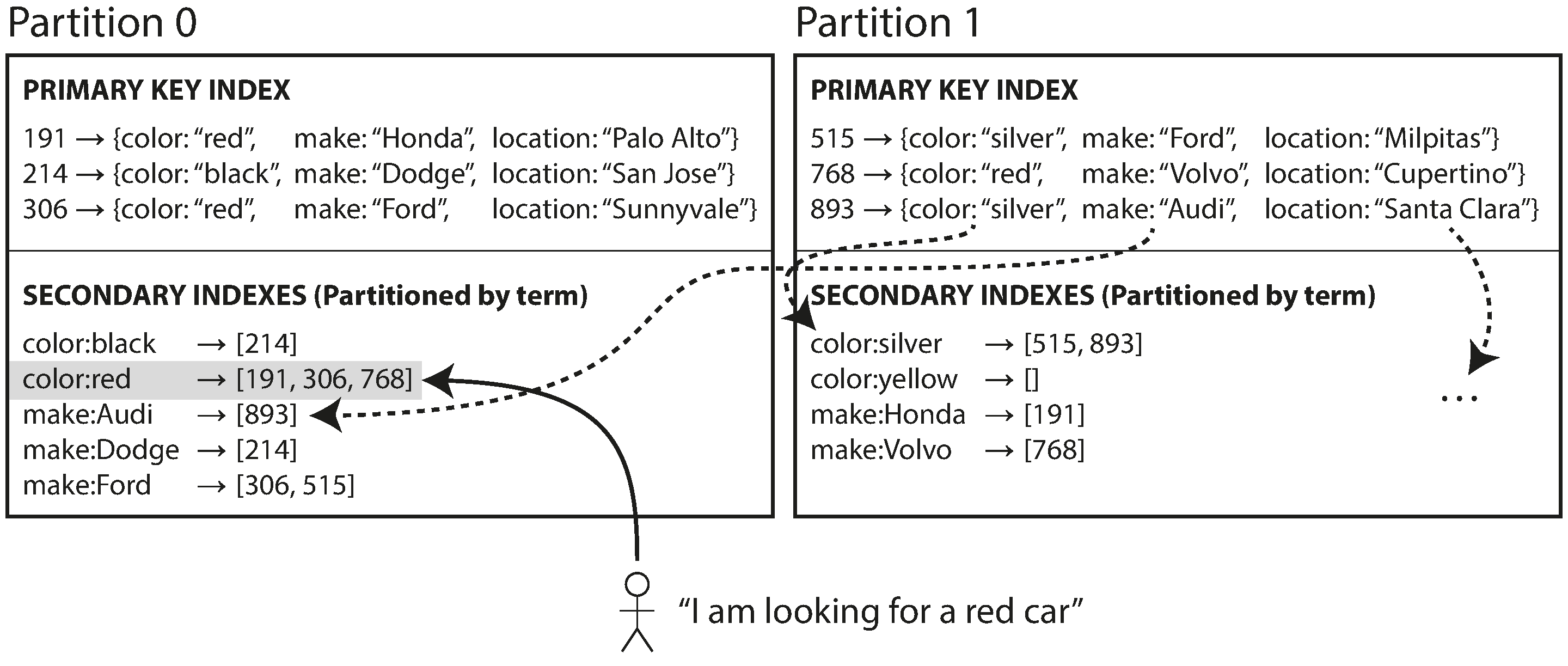
Similar to the document-partitioned approach, the term-partitioned index can be partitioned by the term itself or by using a hash of the term. Partitioning by the term itself proves useful for range scans (e.g., on a numeric property like the asking price of a car), while partitioning on a hash of the term provides a more evenly distributed load.
The benefit of a global (term-partitioned) index lies in more efficient reads. Instead of performing scatter/gather over all partitions, a client can make a request solely to the partition containing the term of interest. However, the drawback is that writes become slower and more complex. A write to a single document may impact multiple partitions of the index, as each term in the document might reside on a different partition or node.
In practical terms, updates to global secondary indexes are often asynchronous. This means that if you read the index shortly after a write, the change may not yet be reflected in the index.