Hash Index
This approach tackles efficient data storage and retrieval for scenarios where data is primarily appended to a file.
Indexing with Hashing
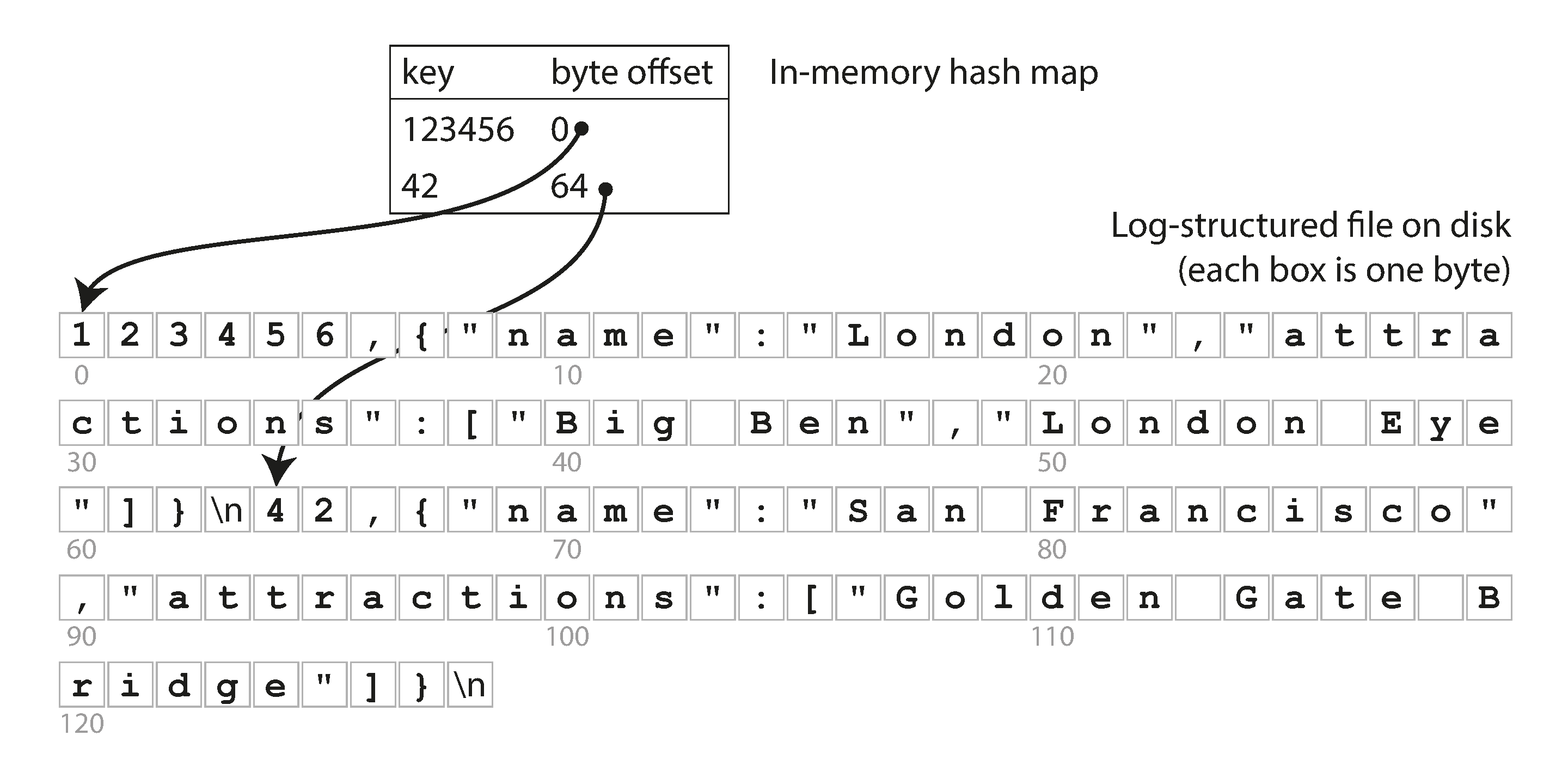
- An in-memory hash table keeps track of key-value pairs and their corresponding byte offsets within the data file.
- Adding or updating a key involves updating both the data file and the hash table.
- Lookups involve using the hash table to find the location of the value in the data file.
Compaction and Segment Management
Data is stored in fixed-size segments. A new segment is created when the current one reaches its size limit.
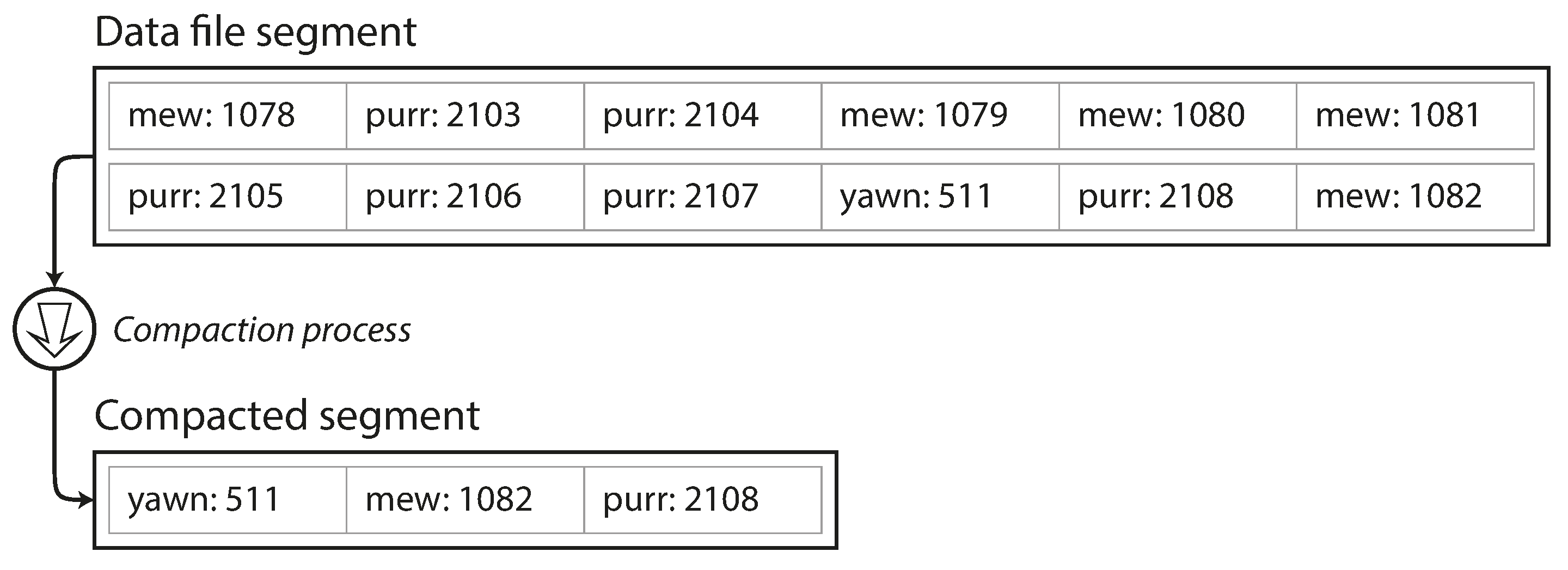
Compaction merges and cleans up segments by:
- Removing duplicate keys (keeping the latest version).
- Merging multiple segments into a single, smaller one.
Compaction and merging happen in the background while reads and writes continue.
After compaction, old segments are deleted, and reads switch to the new merged segment.

How Reads Work
When you want to read data:
- Check the most recent segment’s hash map for the key.
- If not found, check the next recent segment, and so on.
- Return the data from the segment where it is found.
Deletion and Tombstones
To delete a key:
- Append a special deletion record (tombstone) to the file.
- During compaction, any data with a tombstone is ignored.
Additional Considerations
- Crash Recovery: If the database crashes, we lose in-memory hash maps. We can rebuild them by reading segment files from start to end, or by using saved snapshots of hash maps to speed up recovery.
- Partially Written Records: If a crash happens while writing, we use checksums to detect and ignore corrupted data.
- Concurrency Control: Writes are done by a single thread, while multiple threads can read data. This ensures data integrity and simplifies recovery after crashes.
Limitations
- On-Disk Hash Maps: Hard to implement efficiently due to random access I/O and the complexity of handling hash collisions.
- Range Queries: Not efficient. You can’t easily find all keys in a range; you need to look up each key individually.
In summary, hash indexes are great for fast, simple lookups but have limitations in terms of range queries and disk space management. Techniques like compaction and merging help manage disk space and improve performance.